




I. Présentation générale▲

Graphite est une solution de métrologie open source dont le développement a été initié en 2006, et qui s'est progressivement imposée au sein des entreprises comme un substitut aux outils propriétaires souvent peu flexibles et difficiles à mettre en œuvre.
Le projet regroupe un ensemble de trois composants (whisper, carbon et graphite-web), tous développés en Python. Si le déploiement d'un serveur graphite isolé peut s'effectuer de façon raisonnablement aisée, la pérennité de la solution implique dans la plupart des cas la mise en œuvre d'une architecture regroupant de multiples serveurs, et susceptible d'évoluer en fonction des contraintes futures (augmentation de la volumétrie, réplication…).
Dans ce tutoriel, nous allons apprendre, dans un premier temps, la façon dont les données sont gérées au sein d'un cluster graphite. Nous aborderons ensuite les problématiques de migration, à travers l'étude de deux cas concrets :
- migration des métriques d'un serveur unique vers un nouveau cluster composé de deux relais frontaux et trois caches, avec duplication de l'ensemble des métriques ;
- extension d'un cluster existant (ajout de 1 à n caches), en conservant les éventuelles contraintes de réplication.
Les problématiques de migration de données peuvent paraître simples de prime abord, mais la répartition des métriques dans un cluster graphite ne doit rien au hasard, et obéit à des règles précises. Il est donc essentiel de comprendre comment ces données sont gérées afin d'être en mesure de les migrer efficacement le moment venu.
Le projet carbonate regroupe d'ailleurs un ensemble d'utilitaires prévus à cet effet, et nous les utiliserons dans le traitement des exemples. Une précision importante néanmoins : ces outils ne supportent que le consistent hashing comme mode de distribution des métriques, et ne fonctionneront donc pas si vos caches carbon sont masqués par des relais utilisant un fichier de règles (RELAY_METHOD = rules).
II. Les démons carbon▲
Lorsqu'une donnée est reçue par un serveur ou un cluster graphite, les composants impliqués sont d'abord les démons carbon (relais, agrégateurs et caches). Dans le cas de figure le plus simple, la métrique est directement traitée par un cache carbon, et injectée dans un fichier de données whisper. Pour chaque métrique stockée, il existe un fichier whisper dédié. Si plusieurs caches sont déployés sur un même serveur, graphite met en œuvre un mécanisme de routage dont le but est de garantir qu'une métrique donnée sera toujours traitée par un seul et même cache. L'un de ces mécanismes est le consistent hashing.
Prenons l'exemple du cluster ci-dessous :
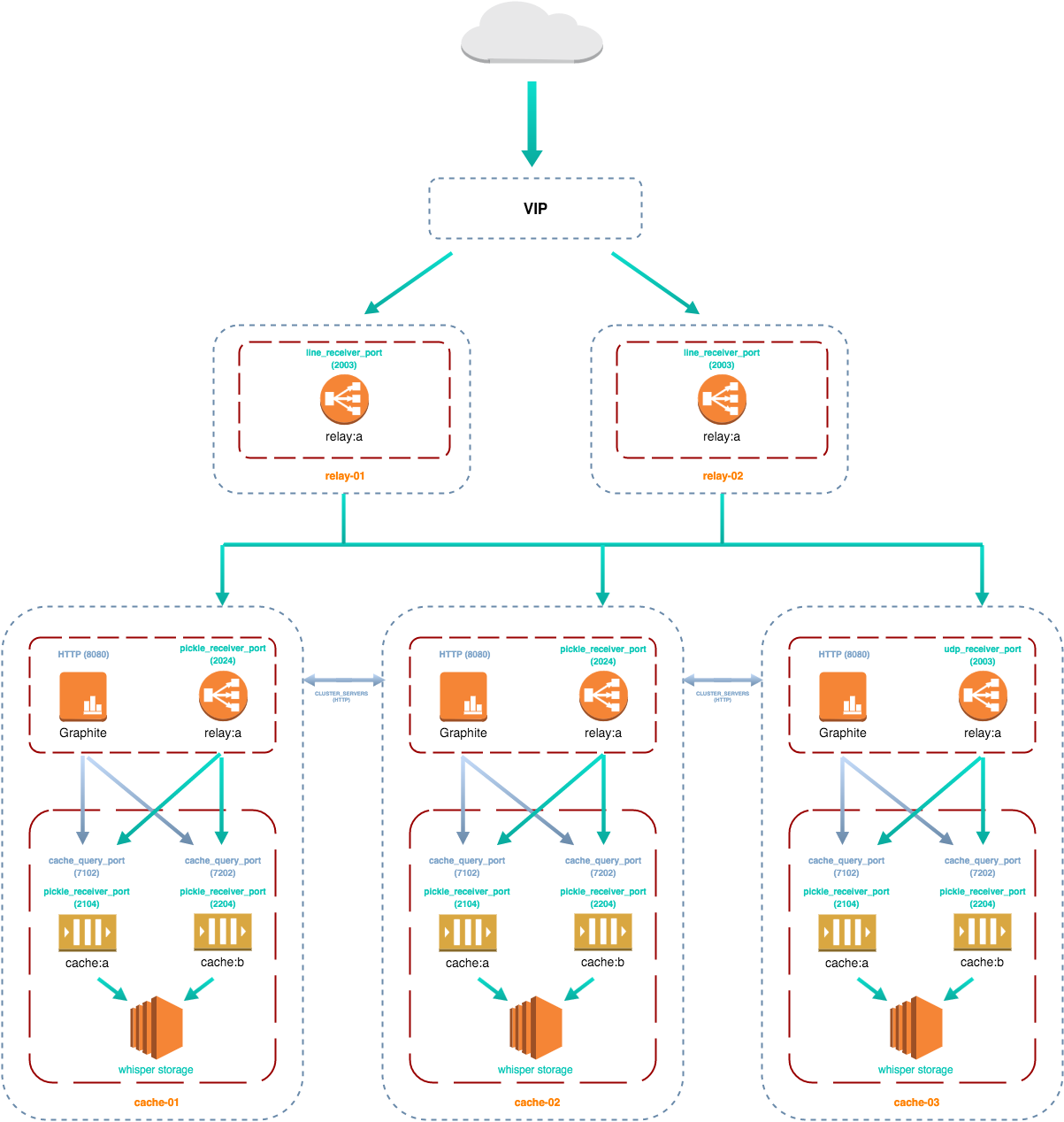
Les métriques sont d'abord traitées par les relais de plus haut niveau (serveurs relay-01 et relay-02). Sur chacun d'entre eux, le paramètre REPLICATION_FACTOR est positionné à 2. Cela signifie que chaque relais transmet les données reçues à deux serveurs de cache distincts, afin d'assurer la persistance de deux exemplaires de chaque métrique. Pour ces relais, la liste des destinations est la suivante :
DESTINATIONS = cache-01:2024:a, cache-02:2024:a, cache-03:2024:aUne destination est composée du nom ou de l'adresse IP de la machine cible, du port d'écoute du démon carbon (ici un relais) et de son identifiant (la lettre 'a' dans ce cas de figure).
Dans la grappe des trois nœuds en charge du stockage, deux serveurs vont donc recevoir la donnée concernée. Le processus carbon-relay s'exécutant sur ces serveurs utilise encore une fois le consistent hashing pour déterminer à quel cache il adresse la métrique. Pour ces relais de second niveau, le paramètre DESTINATIONS référence les caches locaux :
DESTINATIONS = 127.0.0.1:2104:a, 127.0.0.1:2204:bLe consistent hashing permet d'associer à chaque métrique une destination précise et surtout immuable. Il a également pour objectif d'assurer la répartition la plus équilibrée possible des métriques sur l'ensemble des nœuds de stockage. Il est modélisé à l'aide d'un cercle - ou consistent hash ring - que l'on parcourt dans le sens horaire, jusqu'à ce que la correspondance recherchée soit trouvée. Le hash ring d'un cluster garantit ainsi l'unicité de l'association métrique/destination.
III. Implémentation du consistent hashing▲
Le code en charge de la distribution des métriques (pour la topologie qui nous concerne en tout cas) est la classe routers.ConsistentHashingRouter de la bibliothèque carbon. Le routeur maintient lui-même un objet de type hashing.ConsistentHashRing qui permettra aux démons carbon-relay d'assigner telle ou telle métrique à une destination précise.
La première étape dans la construction du hash ring est d'associer des positions (ou points du cercle) aux différents serveurs de stockage, référencés dans le paramètre DESTINATIONS de la configuration des relais frontaux.
Dans le cluster ci-dessus, les nœuds sont donc les suivants :
('cache-01', 'a')
('cache-02', 'a')
('cache-03', 'a')La fonction add_node de la classe hashing.ConsistentHashRing calcule pour chaque nœud une position à l'aide d'une fonction de hachage. En se limitant à une position par serveur, on obtiendrait le hash ring suivant :
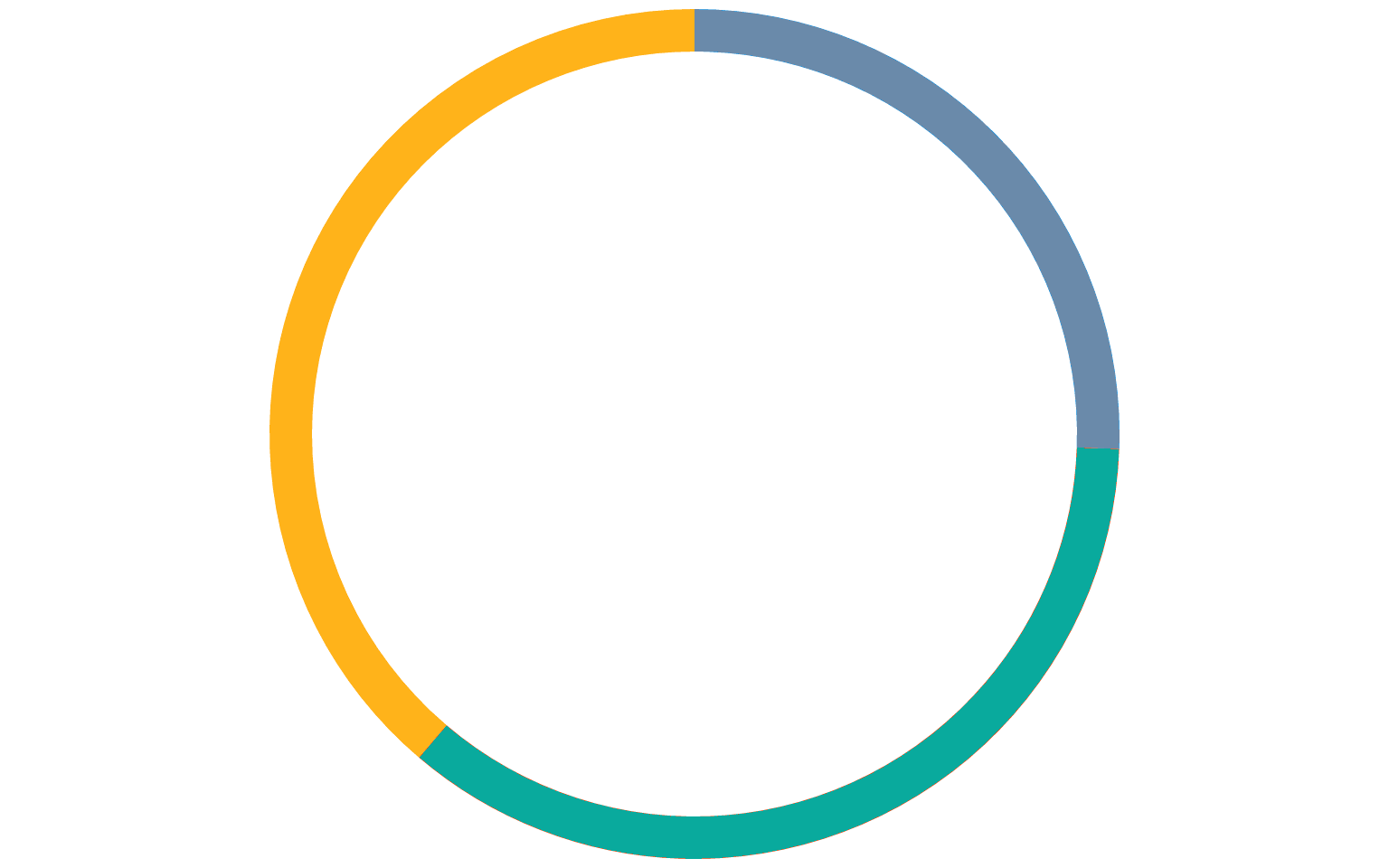
On peut constater que les destinations sont représentées de façon assez inégale, ce qui aurait pour conséquence de créer un déséquilibre dans la distribution des métriques. Pour limiter ce phénomène, la méthode add_node génère par défaut 100 positions par destination, en évitant les éventuelles collisions :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
class ConsistentHashRing:
def __init__(self, nodes, replica_count=100):
self.ring = []
self.nodes = set()
self.replica_count = replica_count
for node in nodes:
self.add_node(node)
def compute_ring_position(self, key):
big_hash = md5( str(key) ).hexdigest()
small_hash = int(big_hash[:4], 16)
return small_hash
def add_node(self, node):
self.nodes.add(node)
for i in range(self.replica_count):
replica_key = "%s:%d" % (node, i)
position = self.compute_ring_position(replica_key)
while position in [r[0] for r in self.ring]:
position = position + 1
entry = (position, node)
bisect.insort(self.ring, entry)
Le hash ring est construit par itérations successives, chaque tuple étant trié en fonction de la valeur de la position :
replica_key : ('cache-01', 'a'):0
position : 7715
entry : (7715, ('cache-01', 'a'))
self.ring : [(7715, ('cache-01', 'a'))]
replica_key : ('cache-01', 'a'):1
position : 42264
entry : (42264, ('cache-01', 'a'))
self.ring : [(7715, ('cache-01', 'a')), (42264, ('cache-01', 'a'))]
replica_key : ('cache-01', 'a'):2
position : 36696
entry : (36696, ('cache-01', 'a'))
self.ring : [(7715, ('cache-01', 'a')), (36696, ('cache-01', 'a')), (42264, ('cache-01', 'a'))]Voici un rendu visuel du hash ring complet pour nos trois destinations :
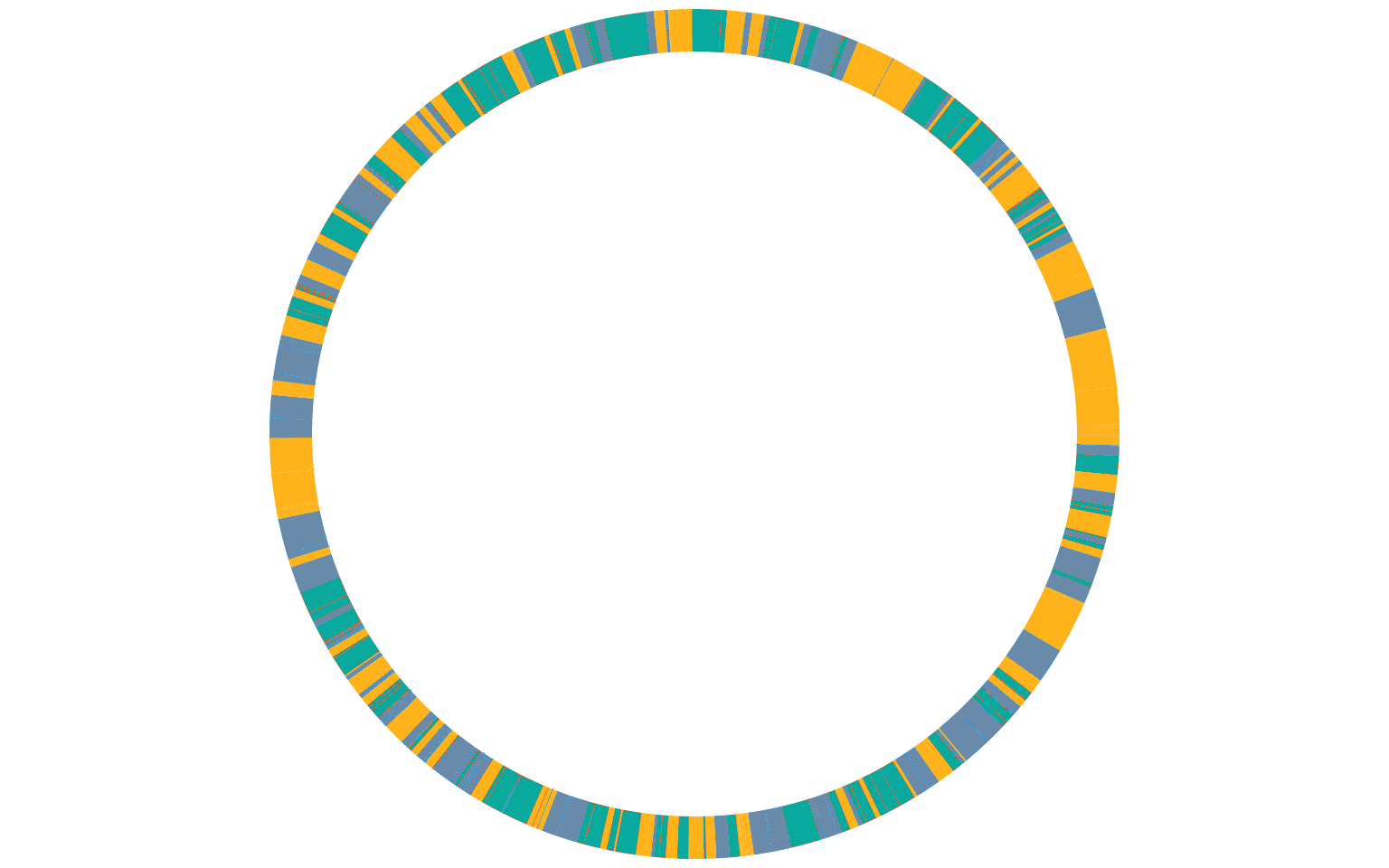
Lorsque le cluster doit définir la ou les destination(s) d'une métrique donnée, une position est calculée de la même façon, la clé étant le nom de la métrique (qui est nécessairement unique au sein du cluster). Pour le hash ring ci-dessus et la métrique : collectd.nginx01.interface.eth0.if_packets.tx, on obtient par exemple la position 9982.
Voici la section correspondante du hash ring :
(9900, ('cache-03', 'a')), (9985, ('cache-03', 'a')), (10185, ('cache-03', 'a')), (10306, ('cache-02', 'a')), (10423, ('cache-01', 'a'))La première destination associée à cette métrique est celle correspondant à la position supérieure suivante (9985), soit le serveur cache-03. Le code qui détermine la liste des destinations (méthode getDestinations de la classe ConsistentHashingRouter) tient compte du REPLICATION_FACTOR (ici 2), et parcourt donc le hash ring jusqu'à rencontrer une seconde destination différente de la première.
Les destinations renvoyées sont en définitive les suivantes :
[('cache-03', 2024, 'a'), ('cache-02', 2024, 'a')]Tant que la topologie du cluster n'évolue pas, le consistent hashing permet donc d'assurer la cohérence du stockage des données.
IV. Migration et consistance des données▲
Revenons maintenant au premier exemple de migration évoqué plus haut : la migration des données d'un serveur graphite unique vers un nouveau cluster de cinq nœuds. La première étape consiste à installer carbonate sur le serveur source et sur les trois serveurs de cache du cluster cible :
$ pip install carbonateUne fois le package installé, il faut - là encore sur chacun des serveurs - créer le fichier /opt/graphite/conf/carbonate.conf, qui décrit l'architecture des clusters (source et destination) :
[old]
DESTINATIONS = graphite:2003:a
REPLICATION_FACTOR = 1
[main]
DESTINATIONS = cache-01:2024:a, cache-02:2024:a, cache-03:2024:a REPLICATION_FACTOR = 2
SSH_USER = carbonLe cluster 'old' ne comprend qu'un nœud, et un démon carbon-cache en écoute sur le port TCP 2003 (configuration par défaut).
Le cluster 'main' intègre les trois nœuds de stockage du cluster cible. La valeur du paramètre DESTINATIONS doit être identique à celle du paramètre DESTINATIONS des démons carbon-relay s'exécutant sur les serveurs relay-01 et relay-02.
Enfin, il faut faire en sorte que l'utilisateur auquel appartiennent les fichiers whisper ('carbon' dans l'exemple) soit en mesure de se connecter en ssh au serveur source (cluster 'old'), à partir de chacun des nœuds du cluster 'main'.
Pour ce qui est de la migration en elle-même, deux approches peuvent être retenues.
Première approche
Effectuer la bascule de l'injection des métriques sans avoir préalablement migré les données (via une VIP ou une modification d'enregistrement CNAME). Cette solution présente les inconvénients suivants :
- la création des nouveaux fichiers whisper va provoquer une saturation des disques du nouveau cluster. Par défaut, whisper alloue tout l'espace requis pour le stockage des métriques lors de la création du fichier, afin d'éviter sa fragmentation et d'assurer ainsi de meilleures performances. Même à raison d'un Mo par fichier, le volume total représenterait par exemple 195 Go pour 200 000 métriques. Afin de minimiser l'impact sur les performances de la création des fichiers whisper, la configuration carbon (carbon.conf) intègre le paramètre MAX_CREATES_PER_MINUTE, dont la valeur est de 50 par défaut. S'il est possible d'augmenter ce nombre de façon sensible, le temps nécessaire à la création de l'ensemble des métriques serait prohibitif, à moins de dégrader considérablement les performances du cluster ;
- une fois l'ensemble des fichiers whisper créés, il sera encore nécessaire de récupérer l'historique des échantillons pour chaque métrique. Cette opération peut être réalisée assez simplement à l'aide des outils carbonate, mais le processus de “backfill” sera très long (insertion de tous les points manquants pour l'ensemble des métriques) et là encore coûteux en termes de performances.
Deuxième approche
Effectuer une première synchronisation des fichiers whisper avant d'injecter les données collectées dans le nouveau cluster. Cette solution présente les inconvénients suivants :
- la première copie des données est effectuée lorsque le système source est encore en activité. Il faut cependant garder à l'esprit que carbonate réalise un transfert des métriques par lots de 1000 fichiers, et que la charge résultante restera mesurée ;
- le transfert des données sera effectué deux fois (copie initiale plus backfill des points manquants).
La seconde solution reste malgré tout la plus avantageuse : on évite d'une part les problèmes liés à la création dynamique des fichiers whisper, et les opérations de backfill (beaucoup plus longues que la copie des données en elle-même) seront plus courtes dans le second cas de figure, puisqu'il ne s'agira d'importer les échantillons manquants que pour la période allant de la première copie à la mise en production du cluster.
Voyons concrètement comment cette stratégie peut être mise en œuvre à l'aide des outils carbonate. Ces outils sont des utilitaires destinés à accomplir chacun une tâche relativement simple, mais dont l'utilisation combinée autorise la réalisation de traitements complexes. La commande suivante permet par exemple de sélectionner les métriques dont la destination cible est le premier nœud du cluster, et d'en effectuer la copie :
$ ssh graphite -- carbon-list |grep -v '^carbon' |carbon-sieve -C main -n cache-01 |carbon-sync -s graphiteDans le détail :
- carbon-list liste toutes les métriques disponibles sur le serveur source (graphite). La liste obtenue est filtrée une première fois afin de ne pas tenir compte des statistiques propres au démon carbon-cache s'exécutant sur cette machine ;
- carbon-sieve applique un second filtrage, qui permet d'obtenir le sous-ensemble des métriques dont la destination cible est le serveur cache-01 ;
- enfin, carbon-sync effectue une copie des métriques résultantes par lots successifs dans un répertoire temporaire de la machine locale (ici cache-01), avant de déplacer le fichier whisper vers sa destination finale ou de procéder à un éventuel remplacement des points manquants si le fichier existe déjà.
Après avoir répété l'opération sur les deux autres nœuds de stockage, tous les fichiers whisper seront convenablement répartis, et on pourra procéder à l'injection des données dans le nouveau cluster. Il faudra ensuite réexécuter chacune de ces commandes pour récupérer les points manquants (période correspondant au laps de temps écoulé entre la première synchronisation des données et la mise en production effective du cluster).
La mise en œuvre du second exemple évoqué (ajout de 1 à n serveurs de stockage à un cluster graphite existant) obéit à la même logique : une première étape de redistribution des fichiers, avant activation de la nouvelle configuration. La seule étape additionnelle consiste à nettoyer les anciens fichiers whisper qui ne seraient plus positionnés sur les serveurs appropriés. Cette opération peut également être effectuée à l'aide de la commande carbon-sieve (en utilisant l'option -I) :
$ carbon-list | carbon-sieve -C main -I -n cache-01La commande ci-dessus renvoie la liste des fichiers qui ne sont plus censés être présents sur le serveur.
V. Conclusion▲
La gestion manuelle d'une base de métriques très volumineuse est souvent délicate, et l'objectif du projet carbonate était précisément d'apporter une solution aux problèmes les plus communs rencontrés lorsque l'on administre un cluster graphite.
Ces outils présentent néanmoins quelques lacunes :
- pas de gestion de la concurrence d'accès lors du transfert des métriques, ou lors des opérations de backfill. Ce point n'est cependant pas critique compte tenu du mode de fonctionnement des démons de cache carbon ;
- des performances qui peuvent s'avérer problématiques dans un contexte de forte volumétrie, notamment lors des opérations de backfill. D'autres projets ont vu le jour pour pallier cette limitation, citons en particulier buckytools.
Note de la rédaction Developpez.com▲
Tous nos remerciements à Wescale pour l'autorisation de publication de ce tutoriel.
Nos remerciements également à Guillaume Sigui pour la mise au gabarit Developpez.com et Claude Leloup pour la relecture orthographique.