



I. Introduction▲
|
|
Les infrastructures sont aujourd'hui souvent en mode « instantané », tous les traitements prennent moins de 200 ms. Les progrès dans les bases de données, les systèmes de fichiers, les CPU permettent de gérer et de construire ce type d'infrastructure. |

Une solution est donc de jouer le dialogue suivant :
- Appelant : je veux exécuter la tâche A.
- API : la tâche A est longue, je vous confirme la réception de la demande, voici un lien permettant le suivi de la tâche.
- Appelant (en boucle) : quel est le statut de ma tâche ?
Une autre solution pourrait être :
- Appelant : je veux exécuter la tâche A, lorsqu'elle est finie, appeler l'API alpha.
- API : la tâche A est longue, je vous confirme la réception de la demande, voici un lien permettant le suivi de la tâche.
- …
- API : la tâche A est finie, j'appelle l'API alpha pour en informer l'appelant.
La deuxième solution est élégante, car il n'y a pas besoin de « poller » mon API, mais nécessite que l'appelant gère lui-même un service REST.
Dans ce tutoriel nous verrons une proposition pour monter une infrastructure de ce type. Elle sera composée de :
- Keystone pour la gestion des utilisateurs ;
- une application « restapi », pour recevoir des demandes, qui sera codée en Python/Flask ;
- un bus « RabbitMQ » permettant l'asynchronisme et la gestion de la pile de tâches ;
- un exemple d'application « worker » en Python ;
- une application « reader » qui permet de récupérer l'état des demandes ;
- une base « REDIS » permettant de gérer un cache.
II. Architecture▲
Un schéma permet d'expliquer l'architecture.

L'application « APIREST » dialogue avec le Keystone pour tester chaque connexion. C'est l'application qui permet pour les clients d'entrer dans le système.
Le bus récupère les demandes des clients et les disperse dans diverses queues. Il permet de gérer les pics de demandes en « cachant » les demandes dans sa pile.
Le REDIS est positionné ici pour permettre de stocker l'état des « jobs » en cours, par exemple on pourrait mettre un « time to live » aux données à une journée. Il ne s'agit pas de créer un référentiel de données qui pourrait être appelé ensuite pour récupérer les objets créés par notre traitement, mais bien d'un cache permettant de stocker les « jobs » en cours ou récents.
Dans cet exemple je n'ai développé qu'un « worker », l'objectif de cette application est multiple :
- plusieurs types de « workers » peuvent coexister en écoutant des queues différentes, ce qui permet de « scaler » finement le système ;
- un type de « worker » pour une action permet de simplifier le développement ;
- chaque équipe de développement de « workers » peut choisir sa technologie grâce à l'approche « Docker » ;
- chaque type de « workers » peut demander aux autres de réaliser une action. Par exemple, un « worker » qui exécute des « playbooks » Ansible peut appeler avant le « worker » qui créé une VM.
Le choix d'utiliser des containers est logique dans cette infrastructure, tout est pensé pour travailler en mode « KISS » pour « Keep It Small and Simple ». C'est-à-dire que toutes mes applications sont sous la forme de briques simples, « scalables », « stateless » bien sûr et pouvant être facilement containerisé.
III. Les applications du marché▲
Dans cette partie nous allons voir quelles applications du marché j'utilise et pourquoi.
III-A. Keystone▲
J'utilise Keystone containerisé via : « garland/docker-openstack-keystone ».
L'idée est d'utiliser pour un déploiement en production un Keystone persistant (ou n'importe quel fournisseur de type IAM) plutôt qu'un Keystone non persistant qui ne va pas garder un état sur vos utilisateurs.
Vous pouvez également monter un filesystem persistant avec Kubernetes et stocker la base sqlite de Keystone directement sur ce filesystem.
III-B. RabbitMQ▲
Installer RabbitMQ sur un stockage non persistant est suffisant dans le cadre de mon projet. En effet, les demandes non satisfaites seront à nouveau soumises par les applications appelantes (pas de SLA).
RabbitMQ peut être clustérisé pour pouvoir répondre à la demande.
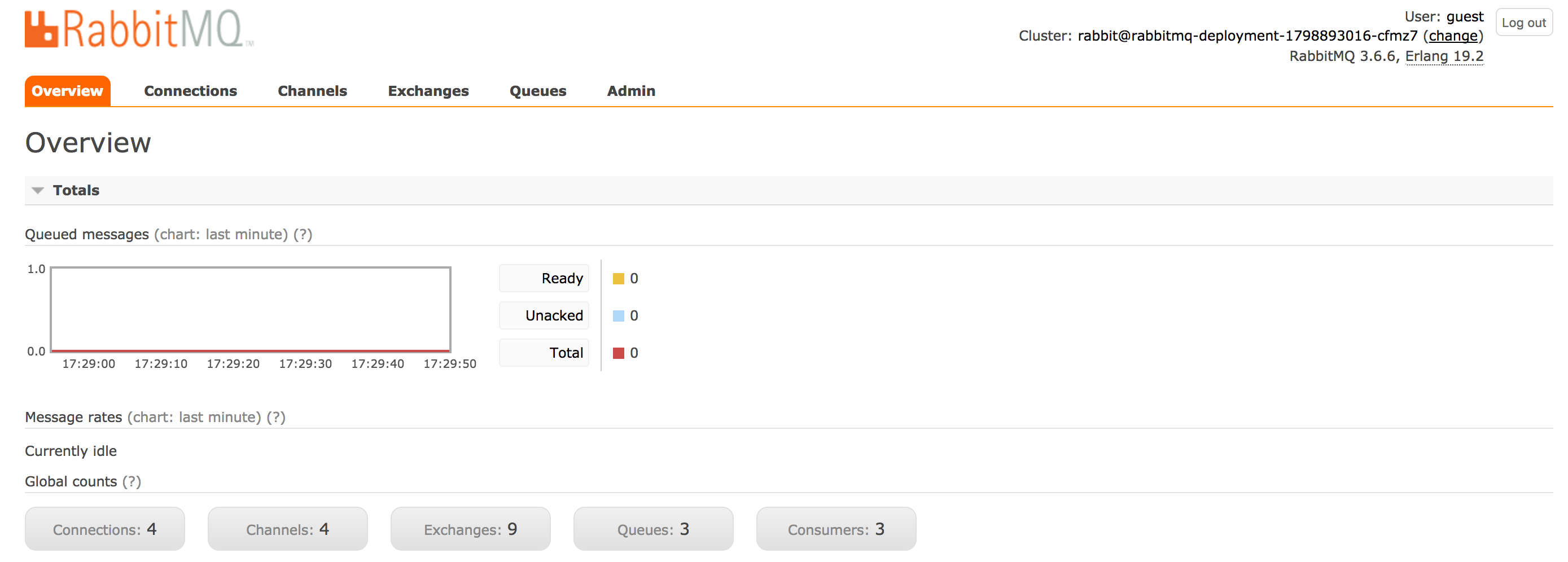
J'utilise RabbitMQ avec son interface de management, qui est pratique pour visualiser les flux du système.
RabbitMQ sera également au centre de mon système de logs et monitoring, l'ensemble des routing keys sera redirigé dans une queue qui sera absorbée par un ElasticSearch.
III-C. Redis▲
REDIS est présent pour gérer un cache management pour l'état des « jobs » en cours et récents et non une base de données qui stocke les résultats des « jobs » sur la durée.
S'il tombe, le cache sera généré par la vie du système, les anciennes données seront perdues.
REDIS est également clustérisable pour pouvoir répondre à la demande.
III-D. Kubernetes▲
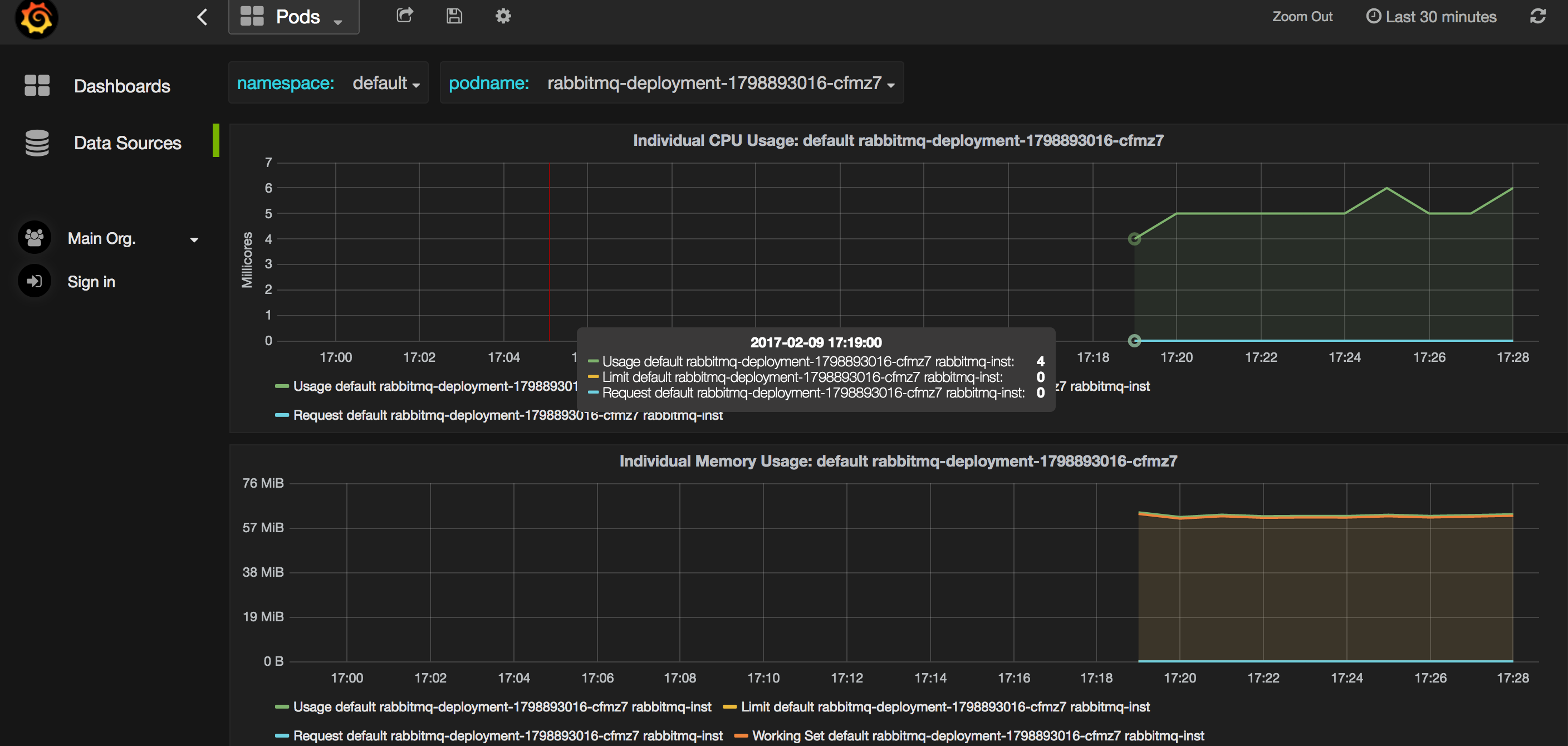
Dans le cadre de ce tutoriel j'ai utilisé « minikube », une solution pratique et simple pour tester Kubernetes en local.
J'utilise deux « plugins » presque indispensables pour monitorer mon Kubernetes : « dashboard » me permet d'accéder au « dashboard » de Kubernetes et « heapster » qui autorise un monitoring fin de mon système (pour le « host » comme pour les services).

IV. Mes applications▲
IV-A. L'application « API REST »▲
Code source de l'application.
Les objectifs de cette application sont :
- récupérer les requêtes des clients ;
- gérer l'authentification des clients, autorisation à l'avenir ;
- contrôler les données envoyées (contrôle de surface) ;
- ajouter les données d'authentification à la demande ;
- dans le cas où il s'agit d'une commande asynchrone, positionner la « routing key » correspondant à la demande et l'envoyer au bus ;
- dans l'éventualité où on est dans un cas synchrone, on peut ici faire un appel direct à une autre API ;
- retourner un code HTTP et un message au client.
Cette application est développée en Python avec Flask pour gérer l'interface REST et Pika pour gérer RabbitMQ.
Le projet Flasgger permet d'inclure un Swagger pour visualiser mes API.

Au niveau de l'organisation du code j'utilise « Blueprint » qui me permet de faire des classes et de répartir mes routes.
Dans un de mes fichiers définissant mes routes :
2.
3.
4.
5.
routes_main = Blueprint('routes_main', __name__)
@routes_main.route('/')
def hello_world():
return "{'hello': 'world'}"
Dans mon « main », j'ajoute mes Blueprint ainsi :
2.
3.
4.
5.
6.
7.
app = Flask(__name__)
app.register_blueprint(routes_vm, url_prefix='/v1/vm')
app.register_blueprint(routes_main, url_prefix='/v1')
app.register_blueprint(routes_connect, url_prefix='/v1')
app.run(debug=True,host='0.0.0.0')
Dans le tag « connect » je trouve mon service de création d'un « token » pour mon « user ».
Dans le tag « vmmanagement » je trouve les appels permettant la création « simulée » de VM.
À noter que lors de l'appel à ma méthode de création de VM, un « uuid » est retourné, et c'est grâce à celui-ci que je peux ensuite vérifier l'état de mon « job ». Dans le cas où un « polling » est fait en attente de la fin du « job », il est absolument nécessaire de créer un identifiant permettant le suivi du traitement.
IV-B. L'application « Worker »▲
Code source de l'application.
L'objectif de cette application :
- récupérer un message dans une queue ;
- traiter la requête ;
- indiquer à la queue que le message a bien été traité (ack) ou en erreur (nack) ;
- si un « callback » a été défini par un autre « worker » ou par le client, appeler ce « callback » ;
- renvoyer un message avec le statut pour le « reader ».
À noter qu'un « worker » peut également avoir des API REST qui ne sont pas appelables par le client, mais peuvent être utilisées par l'application « apirest » ou par un autre « worker ».
Même si c'est le « cœur » de mon application, dans le cadre de cette démo, juste quelques lignes sont importantes.
À chaque réception d'un message sur la queue écoutée, une fonction « callback » est appelée : « on_message ».
Dans le cadre de ce tutoriel, l'application simule le traitement long par une attente de 90 secondes (trop long pour un timer http et assez court pour une démo).
time.sleep( 90 )Ensuite je change l'état de mon message à « SUCCESSFULL » :
message['state']='SUCCESSFULL'enfin je republie mon message vers la queue « reader »:
example.publish_message(message, 'reader')IV-C. L'application « Reader »▲
L'objectif de cette application est de récupérer tous les messages circulant dans le bus.
Elle écoute la queue « reader » à qui on associe l'ensemble des « routing keys » du bus afin de ne rater aucune information.
Les informations de fin de traitements ou d'erreurs peuvent être envoyées directement sur une « routing key » 'reader'.
Pour pouvoir récupérer facilement les données, le choix a été de stocker comme clef l'« uuid » du traitement demandé. Ainsi l'application « restapi » peut facilement récupérer l'information pour le suivi du « job ».
Il n'y a pas de gestion de parallélisme, le dernier « reader » qui écrit dans REDIS sera conservé.
V. Mon « Infrastructure as Code »▲
Code source de l'Infrastructure as Code.
V-A. Utilisation d'un registry local▲
Pour éviter de passer par Internet dès que je veux déployer mon infrastructure, j'utilise une VM avec un « registry » local. C'est utile surtout si vous êtes sur un réseau lent ou que vous ne voulez pas mettre vos containers sur un registre public.
Cette étape n'est pas obligatoire pour notre infrastructure, c'est juste une astuce. Vous pouvez sauter ce paragraphe si cela nous vous intéresse pas.
C'est un « registry » non sécurisé, vous avez donc besoin de modifier la configuration de votre « docker » et d'ajouter :
2.
3.
4.
5.
{
"insecure-registries" : [
"192.168.99.100:5000"
]
}
en remplaçant « 192.168.99.100 » par l'IP de la VM contenant votre « registry » local.
Ensuite il suffit de tagger vos « dockers » images locales et de les « pusher » sur votre « registry ».
Pour pouvoir utiliser ce « registry » dans « minikube », vous devez spécifier :
--insecure-registry=$(docker-machine ip registry-vm):5000V-B. Lancement des applications▲
2.
3.
minikube start --insecure-registry=$(docker-machine ip registry-vm):5000
minikube dashboard
minikube addons enable heapster
On peut ensuite créer nos services facilement.
2.
3.
4.
5.
6.
kubectl create -f minikube/redis.yaml
kubectl create -f minikube/rabbitmq.yaml
kubectl create -f minikube/keystone.yaml
kubectl create -f minikube/restapi.yaml
kubectl create -f minikube/reader.yaml
kubectl create -f minikube/worker.yaml
Pour chacun, je crée :
- un déploiement pour lancer le « docker » correspondant ;
- potentiellement un ou deux services pour exposer ses API en interne et/ou en externe.
Ensuite on attend que Keystone soit « up » pour ajouter le premier utilisateur :
2.
3.
4.
5.
6.
7.
8.
9.
while ! curl -X POST \
--connect-timeout 1 --max-time 10 \
-H "X-Auth-Token:*" \
-H "Content-type: application/json" \
-d '{"user":{"name":"Joe","email":"joe@example.com.com","enabled":true,"password":"1234"}}' \
http://$(minikube ip):$(kubectl get service keystone-management --output jsonpath='{.spec.ports[?(@.port==35357)].nodePort}')/v2.0/users; do
sleep 1
done
La récupération du « plugin » « heapster » est souvent longue, à cause de la connexion à Internet pas toujours rapide…
2.
3.
while ! minikube addons open heapster; do
sleep 1
done
Ainsi, il attendra le temps nécessaire à son succès.
VI. Testons le système▲
Lors de mes tests, je peux utiliser mon interface Swagger ou faire des appels via « curl », par exemple.
VI-A. Création du token▲
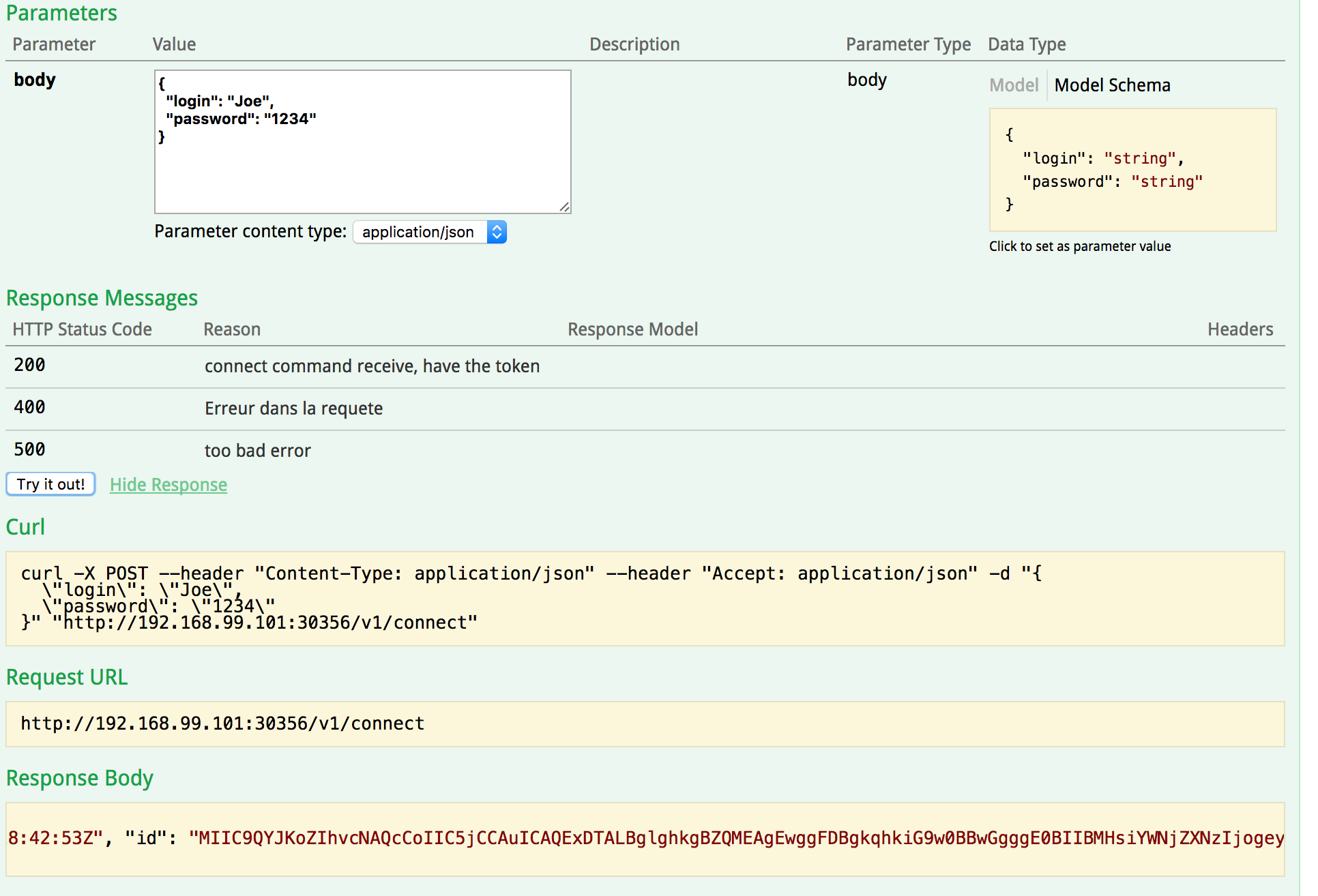
Je peux récupérer mon « token » dans le Json de retour : « access.token.id ».
VI-B. Lancement de la création▲
Pour lancer la création, je passe le « token » via le « header » « X-TOKEN ».
2.
3.
4.
5.
6.
7.
8.
9.
10.
curl -X POST --header "Content-Type: application/json" \
--header "Accept: application/json" \
--header "X-TOKEN: ***" -d "{
\"app_env\": \"DEV\",
\"app_trigram\": \"string\",
\"vm_desc\": \"string\",
\"vm_hostname\": \"lxstring\",
\"vm_profile\": \"Micro\",
\"vm_region\": \"GreaterParis\"
}" "http://192.168.99.101:30356/v1/vm/"
Je récupère bien un « uuid » pour le suivi de mon « job ».
2.
3.
4.
{
"status":"OK",
"uuid":"7fda68b7-b4de-45a6-99fd-57b019cf19ae"
}
VI-C. Récupération de l'état▲
J'appelle mon API avec le « token » dans le « header » « X-TOKEN » et mon « uuid » dans mon URL.
2.
3.
curl -X GET --header "Accept: application/json" \
--header "X-TOKEN: *****" \
"http://192.168.99.101:30356/v1/vm/7fda68b7-b4de-45a6-99fd-57b019cf19ae"
Dans un premier temps je récupère l'action « in progress ».
2.
3.
4.
5.
6.
7.
8.
9.
10.
{
"app_trigram":"string",
"uuid":"7fda68b7-b4de-45a6-99fd-57b019cf19ae",
"app_env":"DEV",
"vm_region":"GreaterParis",
"state":"INPROGRESS",
"vm_profile":"Micro",
"vm_desc":"string",
"vm_hostname":"lxstring"
}
Puis après 90 secondes :
2.
3.
4.
5.
6.
7.
8.
9.
10.
{
"app_trigram":"string",
"uuid":"7fda68b7-b4de-45a6-99fd-57b019cf19ae",
"app_env":"DEV",
"vm_region":"GreaterParis",
"state":"SUCCESSFULL",
"vm_profile":"Micro",
"vm_desc":"string",
"vm_hostname":"lxstring"
}
Ça marche !
Si je teste avec le « mauvais token » je récupère bien un code 401.
VII. Aller plus loin▲
Cette infrastructure nous permet de gérer l'asynchronisme de nos appels ainsi que les éléments de base de notre architecture applicative.
C'est une base de travail qui va vous permettre de recevoir les requêtes des clients et de les traiter de bout en bout. Par exemple, vous allez pouvoir établir des « workflows » entre vos « workers » pour élaborer des tâches plus complexes (en agrégeant des tâches simples). Il y a une réflexion à avoir, pour chaque nouvelle fonctionnalité, pour définir si c'est l'objet d'un nouveau « worker » ou une intégration à un « worker » existant. L'architecture derrière doit répondre à la scalabilité d'un grand nombre du même « worker » ou à la multiplicité de « workers » plus simples.
Pour passer en production il vous faudra mettre en place les éléments sous forme de cluster, en particulier pour RabbitMQ et REDIS. Ces deux éléments permettent la résilience de votre infrastructure, ainsi que la gestion des « logs », « alerting » et monitoring.
VIII. Sources de ce tutoriel▲
Les sources sont disponibles sur GitHub : projet sur le Github de WeScale.
Pour lancer la création de l'infrastructure :
./deploy_kubernetes.shNotes de la rédaction Developpez.com▲
Nous remercions Wescale pour l'autorisation à publier ce tutoriel. Nos remerciements également à Winjerome pour la mise au gabarit Developpez.com et Jacques Jean pour sa relecture orthographique.